
在理想狀態下,當然會想要像前幾天一樣,通通「自己來」:從零開始蒐集資料、設計模型,然後一步一步把它訓練到能用。但現實很骨感,這條路很容易把人榨乾(也會把時間跟錢錢都燒光光QQ)。
這時候 Hugging Face 的出現,猶如耶穌復活。
Hugging Face 被譽為「AI 界的 GitHub」,不僅是一個模型分享平台,更是一個推動開放人工智慧生態的核心力量。自 2016 年成立以來,Hugging Face 從一個聊天機器人新創公司,蛻變為全球最重要的開源 AI 平台之一。它重新定義了研究與實作的邊界,使模型的開發、分享與重現(reproducibility)變得像程式碼協作一樣自然。
Hugging Face 的價值,在於它將「開源」與「社群」結合成一股強大的動能。透過其平台,開發者能自由地上傳、下載與測試數十萬個模型與資料集,涵蓋自然語言處理(NLP)、電腦視覺(CV)、語音辨識、多模態學習等領域。這樣的開放架構不僅加速了研究成果的流通,也讓 AI 的民主化(AI democratization)真正落地。
其中最具代表性的產品 Transformers 套件,讓深度學習模型的應用不再需要繁瑣的訓練流程與龐大的運算資源。開發者只需幾行程式,就能輕鬆體驗文本生成、機器翻譯、情緒分析、影像分類等任務。隨著後續推出的 Datasets、Evaluate、以及以互動式模型展示為核心的 Spaces,Hugging Face 已不只是工具提供者,更是一個完整的 AI 生態系,連結研究者、開發者與企業。
(圖片由 Perplexity 協助生成)
在 Hugging Face 上搜「nutrition」「food」「health」之類的關鍵字,能找到不少模型。常見的應用:
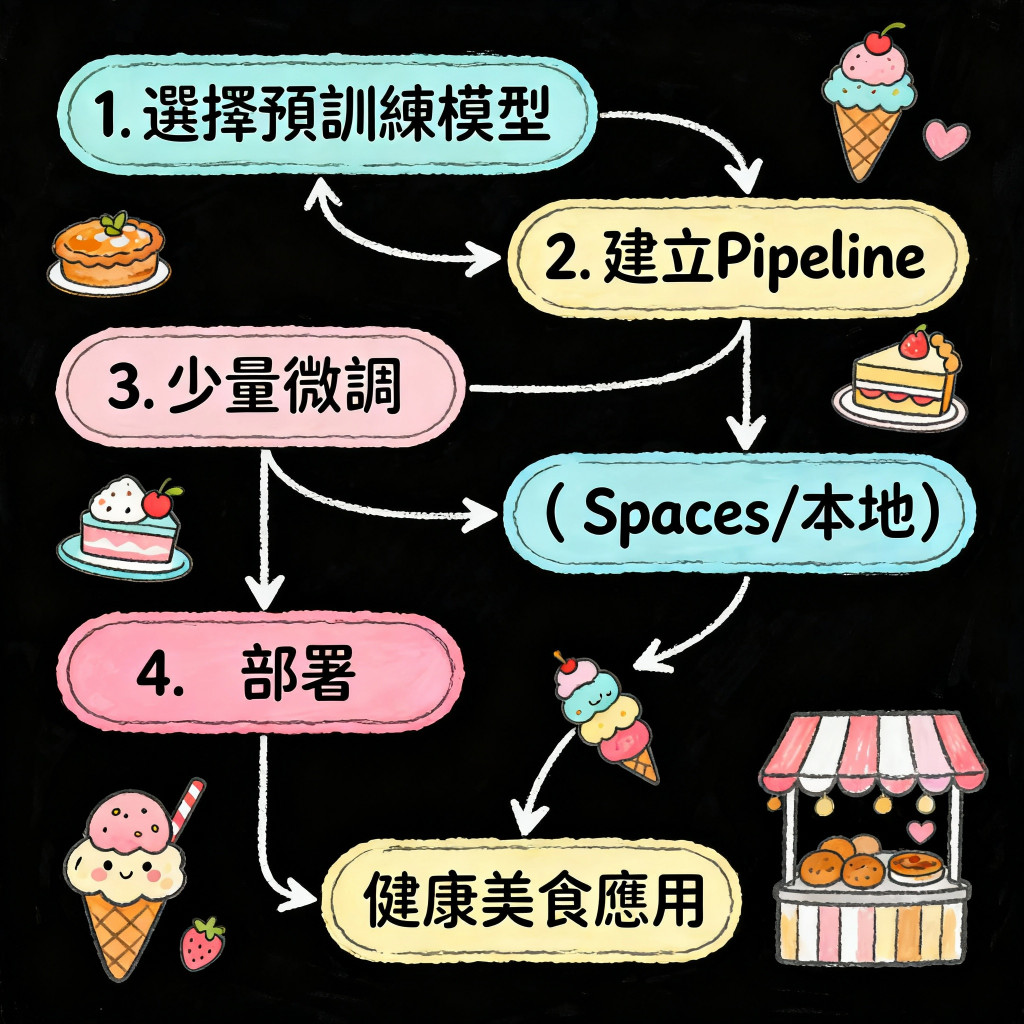
Transformers 一行指令體驗 AI 魔法Hugging Face 的核心精神之一,就是讓 AI 模型「人人可用」。透過 transformers 套件,不需要複雜的訓練流程,就能直接呼叫已訓練好的模型進行推論。以下用程式碼說明如何使用文字分類(text classification)模型:
from transformers import pipeline
classifier = pipeline("text-classification", model="your-chosen-model")
result = classifier("這是爌肉飯,有白飯、爌肉,以及筍乾")
print(result)
在地化微調(Fine-tuning):讓模型更有台灣味在實際應用中,模型雖然強大,但往往「不太理解真實世界」。模型訓練資料主要還是來自英文或國際語料,它就可能會誤解「芋頭」、「番薯葉」、「土豆(花生)」這類台灣在地食材的語意。這時候,就需要透過微調(fine-tuning) 來讓模型更貼近你的應用場景。
微調是一種「在既有模型上進行再訓練」的技術。
不必從零開始訓練整個模型,而是利用現有的預訓練模型(pre-trained model),再用少量與任務相關的資料進一步訓練。
這樣模型既能保留原本的語言理解能力,又能快速學會新領域的知識。
(1) 原始模型學會了「食物」這個概念。
(2) 透過微調,可以進一步讓它學會「滷肉飯」與「爌肉飯」的區別、知道在台灣「鹹酥雞」跟「炸雞」是不一樣的,這些都是台灣夜市文化的重點。
(3) 簡單的說,微調讓 AI 從「懂語言」變成「懂人話」。
只要提供幾百筆台灣食物相關的標註資料,就能讓模型更準確地理解在地語意與文化脈絡。這種「在地化調校」的過程,正是讓 AI 真正貼近使用者生活的關鍵。
在完成模型訓練與微調後,下一步就是「部署(deployment)」:也就是讓更多人能在網頁上直接體驗成果。過去,部署 AI 模型往往需要伺服器設定、後端 API 開發與前端整合,但現在透過 Hugging Face Spaces、Gradio、或 Streamlit,開發者能以極低門檻,快速打造互動式的 AI 展示頁面。
明天(Day9)會有 Spaces 的部署實作
如果有無限資源,誰不想從零開始訓練模型。但「理想很美好,現實很殘酷」,相比之下,直接用 Hugging Face 的預訓練模型才是比較務實的選擇。
| 項目 | Hugging Face 預訓練模型 | 自行訓練模型 |
|---|---|---|
| 成本 | 低(多免費/公開模型) | 高(雲端/GPU租用/工程人力) |
| 速度 | 極快(即取即用) | 較慢(資料收集+標註+訓練) |
| 社群支援 | 活躍、官方支援、自動更新 | 需靠自己/社群發問 |
| 客製化程度 | 中(可微調但限制多) | 高(全流程自定義) |
| 資料來源透明度 | 高(公開、附註出處) | 視自己設計,彈性大但需自管 |
